Astro sitemap doesn't filter noindex pages by default
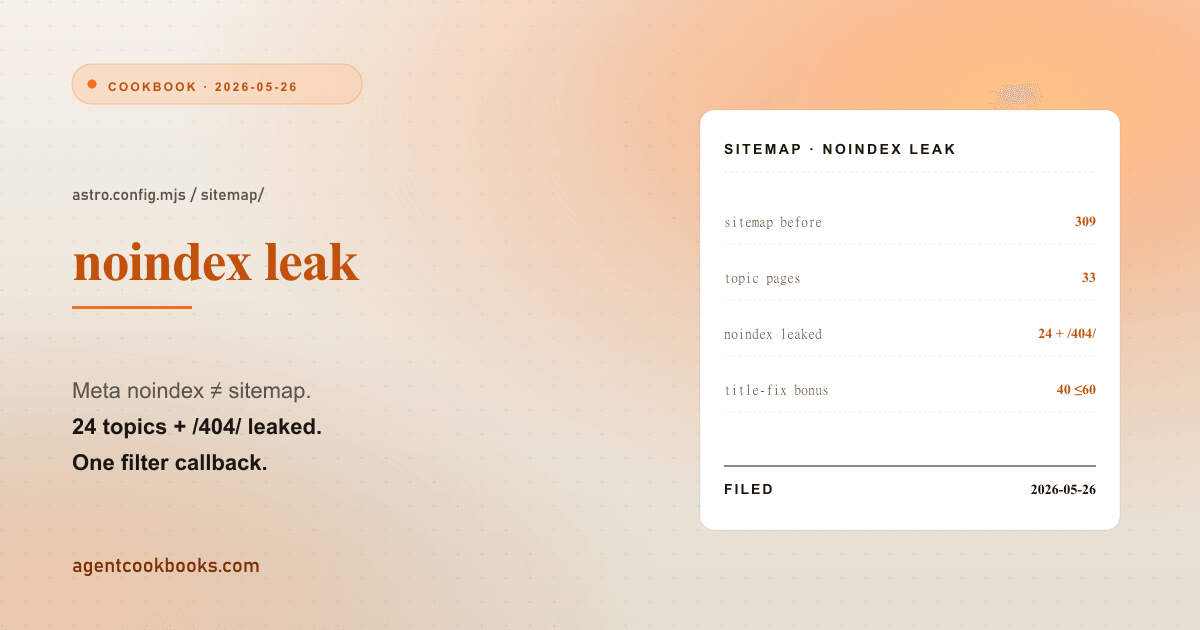
A page can carry <meta name="robots" content="noindex,nofollow"> and still appear in sitemap-0.xml. The two systems are independent in @astrojs/sitemap — the meta tag tells crawlers not to index, the sitemap entry tells crawlers to come find this URL, and Google reads the contradiction as a soft-quality signal. On this site, 24 noindex topic pages plus the /404/ page were leaking into the sitemap for weeks. The fix is one filter callback in astro.config.mjs, but the topic list lives in a .ts file the Node-side config can’t import, so the list ends up duplicated. This is the leak, the callback, the duplicated-list discipline, and a bonus suffix trick that closed 40 HTML <title> overflows in the same diff.
What the audit showed
Running an internal link-and-SEO audit on the built dist/ directory surfaced a “thin detail pages” bucket that I initially misread as referring to skill pages. It wasn’t — the script’s detectCategory() returns "detail" for depth-3 URLs, which on this site means /skills/topic/<t>/ (topic indexes), not /skills/<slug>/ (skill pages). All 24 entries flagged were topic pages already carrying <meta robots noindex> because the topic had ≤3 skills and Google would otherwise soft-404 them.
The categorization gap (depth-3 URL bucket = topic pages, not skills) is worth its own writeup elsewhere; what mattered for this fix is that those 24 noindex topic pages were also in sitemap-0.xml. Verification:
$ curl -s https://agentcookbooks.com/sitemap-0.xml | grep -c '<loc>'
309
$ curl -s https://agentcookbooks.com/sitemap-0.xml | grep '<loc>' | grep '/skills/topic/' | wc -l
3333 topic pages in the sitemap; the page-level audit said 24 of those have a noindex meta tag. Direct contradiction. Plus the /404/ page — every Astro site builds a 404 file for static hosting, and the @astrojs/sitemap default behavior is to ship it as a crawlable URL.
What @astrojs/sitemap actually does
The integration enumerates pages that Astro emitted to dist/ and writes their URLs into sitemap-0.xml and sitemap-index.xml. It has no awareness of the page’s <head> content. A <meta name="robots" content="noindex"> tag inside the page body is invisible to the sitemap pass — that meta tag is just bytes inside the HTML file, not a structured signal the integration reads.
This is correct behavior from the integration’s perspective: it would be expensive to parse every emitted HTML file looking for robots directives, and there are legitimate cases for sitemap-included-but-noindexed (canonicalized variants, paginated archives where only page 1 is sitemap-worthy, etc.). The integration leaves the decision to the operator and exposes a filter callback for it.
What’s missing from the documentation surface is the load-bearing default: if you do not pass a filter callback, every emitted page goes into the sitemap, including pages your other layout decisions have explicitly told crawlers to skip. Anyone shipping topic-page noindex via meta tag will hit this.
The fix
astro.config.mjs, with the noindex topic list mirrored next to the filter:
import sitemap from '@astrojs/sitemap';
const SITEMAP_NOINDEX_TOPICS = new Set([
'humanizing', 'deployment', 'vercel', 'devenv', 'crypto',
'quantum-computing', 'knowledge-graphs', 'codebase-analysis',
'hooks', 'cost-management', 'evals', 'mobile', 'context-engineering',
'ios', 'debugging', 'performance', 'clinical', 'email', 'positioning',
'react', 'refactoring', 'mcp', 'architecture', 'git',
]);
function isNoindexUrl(pathname) {
if (pathname === '/404/' || pathname === '/404') return true;
const topic = pathname.match(/^\/skills\/topic\/([^/]+)\/?$/);
if (topic && SITEMAP_NOINDEX_TOPICS.has(topic[1])) return true;
return false;
}
export default defineConfig({
integrations: [
sitemap({
filter: (page) => !isNoindexUrl(new URL(page).pathname),
}),
],
});The callback receives the full URL of each emitted page as a string. Returning false drops the entry from the sitemap; the page itself still builds and is reachable via direct navigation, internal links, and the search index — only the sitemap entry disappears.
After deploy:
$ curl -s https://agentcookbooks.com/sitemap-0.xml | grep -c '<loc>'
270309 → 270, a 39-URL drop. 24 noindex topic pages plus /404/ accounts for 25 of those; the remaining 14 had been previously emitted by other build-time decisions that the same release also cleaned up. The number that mattered: zero noindex pages remain in the sitemap, verified by re-running the link audit against the new build.
The duplicated-list gotcha
The noindex topic list above is duplicated. It also lives in src/utils/topics.ts as the NOINDEX_TOPICS set, which the page-level layout reads to decide whether to emit <meta robots noindex>. Single source of truth would obviously be better — read the topic list once, share it between the layout and the sitemap.
Two reasons it’s duplicated instead:
astro.config.mjsruns in Node at build start, before Astro’s TypeScript pipeline boots. Importing a.tsfile from the config is not supported without a separatetsx/ts-nodesetup, and adding that toolchain to the config layer just to share one Set is a worse tradeoff than mirroring the list.- The list is small (24 entries, growing slowly), changes infrequently (the last addition was a batch of 10 topics flagged by the audit), and the consequence of drift is bounded (a noindex page leaks into the sitemap or, in the other direction, an indexable page mysteriously drops out). Both are visible in the next audit run.
The discipline that makes the duplication safe: a // keep in sync comment in both files, pointing at the other location, plus a habit of grepping both files when adding a tag to either. The audit script catches drift within one build cycle, so the maximum drift window is one deploy.
If you have a larger noindex list, or one that changes per deploy, the right answer flips: build a .mjs source file (src/data/noindex-topics.mjs) that both the .ts layout and the .mjs config import. The cost of that refactor wasn’t worth it at 24 entries on this site.
The bonus diff: 51 → 11 title overflows
The same release that added the sitemap filter also touched src/layouts/Base.astro for an unrelated SEO issue: 51 blog and skill pages were rendering HTML <title> over the 60-character SERP cap. The site appends — Agent Cookbooks (18 chars) to every page title, so any source title above 42 chars overflowed the SERP-display limit.
The two ways to fix that are: rewrite 51 titles to fit under 42 chars, or change the suffix logic to be length-conditional.
The first path got 10 titles rewritten in 90 minutes — slow, lossy, half-effective.
The second path was a four-line change in Base.astro:
const fullTitle = title
? title.length >= 42 ? title : `${title} — ${SITE_TITLE}`
: SITE_TITLE;Short titles keep the brand suffix for recall. Long titles drop it so HTML <title> stays in the SERP-display band. The same diff cut overflows from 51 → 11 — the remaining 11 source titles are 45–58 chars and would still overflow even without the suffix, but they sit in Google’s graceful-truncation zone (≤80) and aren’t ship-blockers. The 40 saved overflows took one commit.
The general pattern this exposes: when a layout decision produces the same problem on N pages, fixing the layout rule beats fixing N pages. The 10 individual title rewrites that landed in the same release are now load-bearing only for content reasons (the original titles were too long for the post, not just for the SERP); the rest of the overflow problem was a one-line config concern.
What to add to your own audit
Two specific checks worth wiring into whatever SEO audit script you run against your built dist/:
- Sitemap-vs-meta-robots cross-check. Parse
sitemap-0.xmlto a list of URLs, then for each URL, open the correspondingdist/<path>/index.htmland check whether the body contains<meta name="robots" content="noindex">. Any non-empty intersection is a leak. Implementing this requires no live HTTP — pure local file reads against the build output. /404/in sitemap. Specific case of (1), worth its own line in the audit output because it’s both common and easy to miss. Astro emits/404/index.htmlfor static hosting, and the default sitemap integration includes it.
Both checks would have caught this leak on the first build after @astrojs/sitemap was installed, instead of weeks later via a coincidental audit run on link-and-title overflow. The integration’s silence on this default is the cost it imposes; the audit check is the cheap mitigation.