Cloudflare's AI Audit silently rewrites your robots.txt
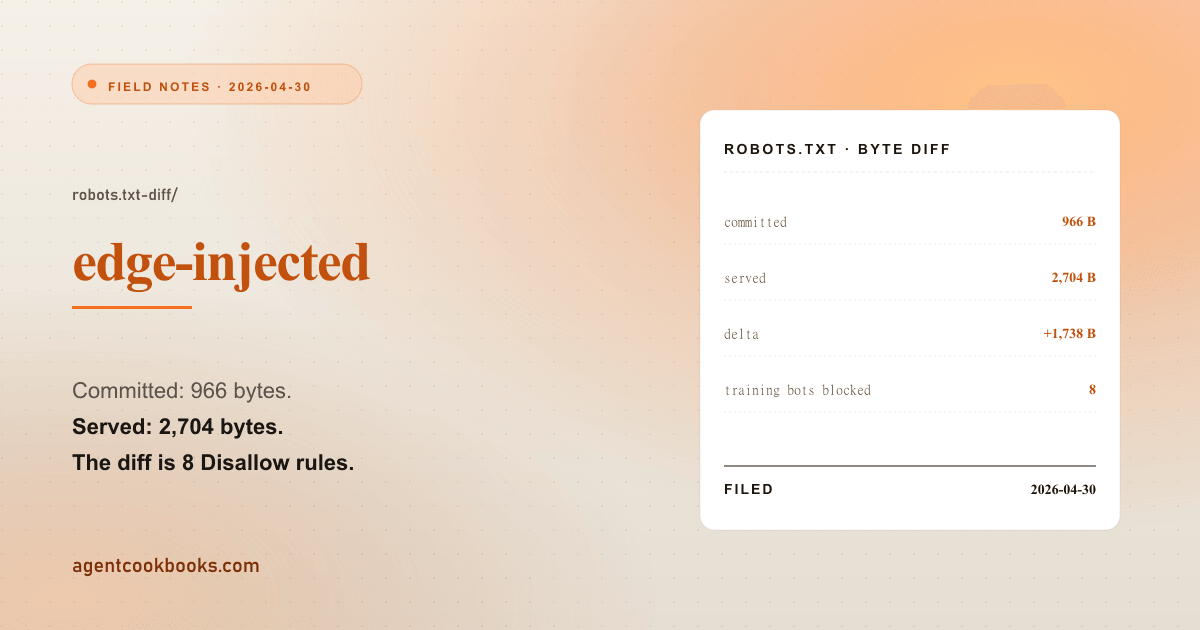
A clean Astro site with a hand-curated robots.txt opening every AI crawler. curl https://agentcookbooks.com/robots.txt comes back 2,704 bytes. The committed public/robots.txt is 966. The difference is a # BEGIN Cloudflare Managed content block that flips eight AI-crawler Allow: / rules to Disallow: / — edge-injected, on by default, and not in the /seo-technical checklist. Training-data ingestion gets blocked for ClaudeBot, GPTBot, Google-Extended, Applebot-Extended, CCBot, Amazonbot, Meta-ExternalAgent, and Bytespider. Real-time browsing slips through: ChatGPT-User, Perplexity-User, and Googlebot itself are untouched, which means Google AI Overviews still index normally. The framework checklist that loaded for this audit doesn’t have a “CDN-managed crawler policy” lane — every audit category said robots.txt: present ✓ while the contents were being silently rewritten at the edge. The fix turned out to be two Cloudflare dashboard toggles, but the finding only surfaced because the byte counts disagreed.
What I ran
/seo-technical from AgriciDaniel’s claude-seo repo — a nine-category technical-SEO audit (crawlability, indexability, security, URL structure, mobile, Core Web Vitals, structured data, JS rendering, IndexNow). Trigger phrase: “technical SEO audit on the live site.” The site went live earlier the same day after a custom-domain attach to Cloudflare Pages, so this was the first live-URL run instead of source-tree static analysis.
Inputs: raw curl against home / blog / skill pages, response headers, sitemap-index, and /robots.txt. No browser, no cookies, no operator IP.
What happened
The skill loaded ~210 lines of framework, including an AI Crawler Management subsection that turned out to be the load-bearing piece: a labeled taxonomy of every major AI bot with explicit notes on what blocking each one costs you. The single most useful line: “Blocking Google-Extended prevents Gemini training use but does NOT affect Google Search indexing or AI Overviews — those use Googlebot.”
Then /robots.txt came back 2,704 bytes. The committed file is 966.
The Cloudflare prepend (paraphrased to fit):
# BEGIN Cloudflare Managed content
User-agent: ClaudeBot
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# END Cloudflare Managed contentBelow that, the operator’s own block — explicitly Allow: / for those same crawlers. RFC 9309 says well-behaved crawlers pick the most-specific rule, but in practice many merge to the most-restrictive. Outcome: the GEO strategy documented in public/robots.txt gets silently inverted at the edge.
What’s actually closed vs open, read through the skill’s taxonomy:
- Closed: training-data ingestion for Anthropic (
ClaudeBot), OpenAI (GPTBot), Google Gemini (Google-Extended), Apple Intelligence (Applebot-Extended), Common Crawl (CCBot), Amazon (Amazonbot), Meta (Meta-ExternalAgent), Bytedance (Bytespider). - Open: real-time browsing —
ChatGPT-User,Perplexity-User, and any crawler not on Cloudflare’s list. Also open:Googlebotitself, which means Google Search and AI Overviews are unaffected (AI Overviews use Googlebot, not Google-Extended).Bingbotand Microsoft Copilot also untouched.
That distinction is the difference between zero AI visibility and partial citation possible via the live-browse path — and it would not be legible without the skill’s taxonomy. A generic “AI bots blocked” finding would have over-stated the damage.
Where it drifted
The skill’s framework doesn’t have a “CDN-managed crawler policy” lane. Cloudflare’s AI Audit / Content Signals feature ships on by default for Pages projects, prepends to /robots.txt at the edge, and contradicts whatever you committed without a deploy-time signal. Akamai and Fastly are rolling out similar features in 2025–2026. None of the nine categories the skill enumerates anticipates this — the framework was built when robots.txt was assumed to be operator-controlled.
The only reason the finding surfaced was reading the actual response. A checklist-driven pass — “robots.txt: present? ✓” — would have logged a green check on the literal presence of a robots.txt and missed that its contents were being rewritten in transit. That’s a structural gap, not a skill bug. Worth knowing for any audit that loops over a category list.
The other observed friction: about half the categories were noise for this run. Mobile, Core Web Vitals, IndexNow, and JS rendering didn’t apply (static Astro, no CrUX data on a same-day-live site, IndexNow not implemented). The skill doesn’t have a “skip if not applicable” mode — you read past the categories that don’t fit. Not blocking, but the audit ran shorter than the framework implied. The companion run on the same site with /seo-page, /seo-audit, /seo-content hit the same shape — frameworks size for full coverage, real audits use a fraction.
What I’d change
Two takeaways for any technical-SEO audit on a CDN-hosted site.
Read the actual response, not just the framework. The Cloudflare prepend was caught by curl and a byte-count diff against the committed source — not by running the skill’s checklist. For any site behind a CDN with crawler-policy features (Cloudflare AI Audit, Akamai Bot Manager, Fastly’s similar work), do the byte-count diff before running the audit. If the live robots.txt is bigger than the committed one, something injected.
Use the AI-crawler taxonomy to grade what’s blocked. “AI bots blocked” is a near-meaningless finding. Training-data ingestion blocked but real-time browsing intact is actionable — it tells you the recovery path is to rely on ChatGPT-User / Perplexity-User / Googlebot for citation while you decide whether to flip the Cloudflare toggle. Without the taxonomy you over-call the severity.
The fix on this site was a Cloudflare dashboard toggle: Security → Bots → AI Audit (disable) plus Manage your robots.txt → Disable robots.txt configuration. The latter is a separate switch that can leak directives even when AI Audit is off — both belong off if you want the committed public/robots.txt to be the single source of truth. After the toggle, /robots.txt came back 966 bytes, byte-for-byte identical to source.