From breadth to depth: pausing wiki imports at 12 sources
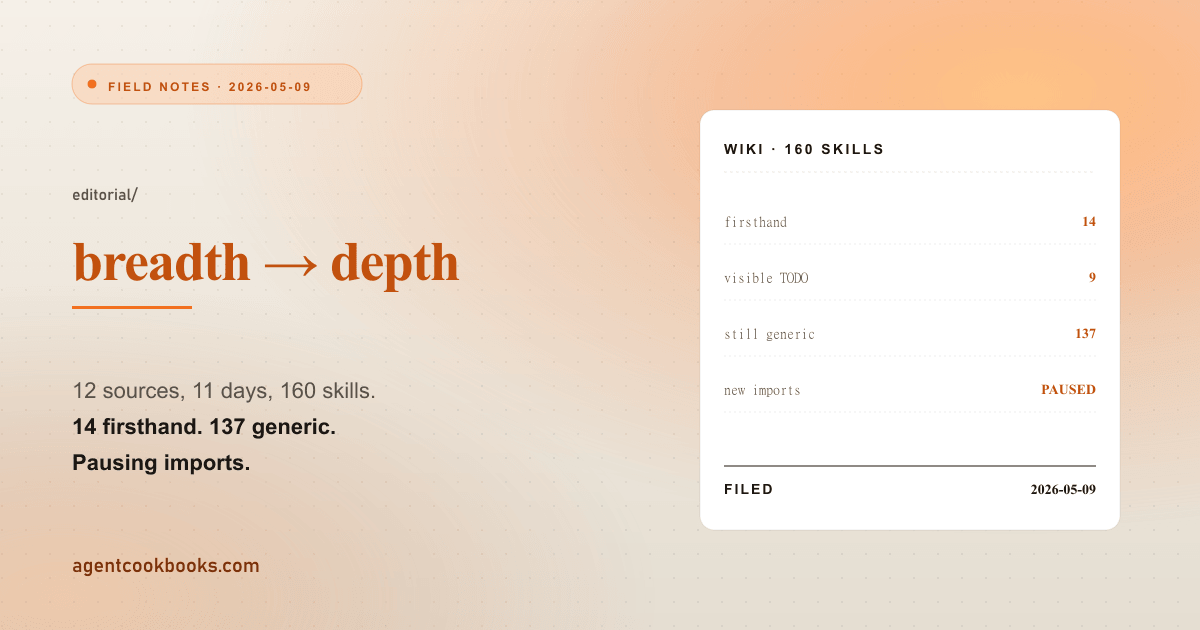
Between April 26 and May 5, the wiki grew from zero to 160 skills across 12 attribution sources — Pocock, Vercel Labs, Rezvani, Haines, AgriciDaniel, obra, K-Dense AI, blader, CosmoBlk, Sitarzewski, hugohe, Osmani. As of May 6, the editorial state was uneven: 14 firsthand, 9 visibly TODO-chipped, 137 still-generic. The expansion phase paid for the index pages, the topic chips, the search corpus. It also produced a long tail of plausible-generic Receipts that don’t meet the site’s editorial bar. This post is the receipt for the decision to stop adding new sources and switch the work to depth.
What I ran
The actual workflow that surfaced the decision: a 160-skill receipts audit dispatched to an Explore agent, asked to bucket every wiki page by Receipts quality. Three buckets, one query, no judgment calls inside the agent — just count what each ## Receipts section contained.
The output:
firsthand: 14 real session notes with config / numbers / failure modes
todo: 9 visible "TODO — to be filled in from a real session" chip
generic: 137 plausible-generic prose, no firsthand artifact
total: 160The 14 firsthand split: 5 from the original launch (the SEO trio plus two early Claude Code skills), 9 newly promoted in commit 2a5a1d7 from the persona-emulation dispatch — every one of those nine scoped to a specific artifact on this site.
The 9 TODO entries are visible-by-design: a chip on the index table reading “TODO” rather than a — dash, with the page itself saying “real notes coming” instead of plausible filler. Transparency over polish, on purpose — a visible TODO reads as honesty, while plausible-generic Receipts read as confidence the page hasn’t earned.
The 137 generic entries are the long tail. Each ships a Receipts section that describes what the skill typically does in a session, no fabricated specific metrics, no firsthand artifact. They were imported as a deliberate trade-off — launch the topical verticals, accept the weaker editorial bar on bulk imports, replace as real engagements happen.
What happened
Two pieces of evidence shifted the math on adding a thirteenth source.
The CF analytics signal. Four days post-domain-attach, the dashboard showed GPTBot crawled 425 requests in 24 hours, +3,763% over the prior period — a full-site sweep of the 229 built pages plus repeated sitemap fetches. ClaudeBot stayed at 5–10/day; Googlebot had spiked +406% earlier in the week. AI search engines are actively indexing the corpus. AI search citations are 1–4 weeks latent — the citation window from the May 1 indexing peak runs through the end of May.
The dilution math. Each new bulk import adds N pages, of which ~all are generic at import time. The ratio of firsthand to generic moves the wrong way. At 12 sources / 137 generic, the wiki’s median skill page has plausible-generic Receipts. A thirteenth source (unless it fills a specific topical gap) makes the median worse, not better.
When the inbound traffic is human-only and pre-launch, additional bulk imports have a positive return — they fill the index, generate topic chips, populate llms.txt. Once AI crawlers are actively indexing, the citations land on whichever page is most extractable for the query. If the most-extractable page on a topic has generic Receipts, the citation is for a generic claim. If it has firsthand Receipts, the citation is for a real artifact. Same crawl, different shape of proof shipped to the user.
The decision: stop adding new sources for the next two weeks. Re-evaluate at ~80 generic (roughly half the backlog cleared) — at that point the dilution math may shift again.
Where it drifted
Two specific moves earn the time freed up.
Generic → firsthand conversion, but only from real engagements. When a real session actually uses one of the 137 generic skills, the receipts get captured in receipts-drafts/<slug>.md and promoted to the wiki. The trap to avoid is running skills synthetically just to fill receipts — that produces a different kind of plausible-generic, with the appearance of firsthand work but no real engagement behind it. The promotion isn’t gated on quantity; one real conversion this week beats five contrived ones.
Cookbook-style blog posts. Config + measured number + named failure mode. Each strengthens the receipts-first wedge in a way no skill import does. Two are queued from the SEO findings on April 30 — a hooks case study (because “Claude Code CRO” is a nearly uncontested SERP gap) and a CRO-with-receipts post tied to the 4-skill content audit lens stack. Cookbook posts compound: each one becomes citation-ready content for the AI crawlers that just started full-site sweeps, and each links back to specific skill pages in a way that justifies their existence in the citation chain.
The thing not to do: change strategy based on week-1 traffic post-deploy. The first bot wave is what bot waves do. The signal worth reading is the four-week mark, when AI citations have had time to land. Re-check ChatGPT and Perplexity for site mentions around the end of May — that’s the real evidence on whether the citation flywheel is starting.
What I’d change
The expansion phase wasn’t a mistake. The wiki needs a critical mass of skills before topic chips, search, and llms.txt have anything to point at. Importing 160 from 12 sources in eleven days got the structure built. The mistake worth avoiding now is treating that velocity as the steady state. Three days after the decision, the wiki is at 167 skills (7 added from in-flight imports already in the queue when the freeze landed) — 9 with explicit firsthand chips, 16 visibly TODO-chipped, the remaining 142 unchipped. The TODO-chip count grew because new imports kept the chip-shaped honesty on this side of the freeze, not because the firsthand pipeline stalled.
If a thirteenth source comes up between now and the re-evaluation point, the question to ask isn’t “is this source MIT-licensed and Claude-Code-relevant?” — most are. The question is “does this source fill a specific topical gap, or does it dilute the median further?” Testing and observability are under-represented; a source there earns its place. Another marketing-skill batch doesn’t.
The 137 generic entries don’t get hidden, deprecated, or downgraded. They stay live. They just stop being treated as the work product. The work product, for the next two weeks, is the small set of pages that can ship one real artifact.