We fact-checked the Opus 4.8 launch with Opus 4.8
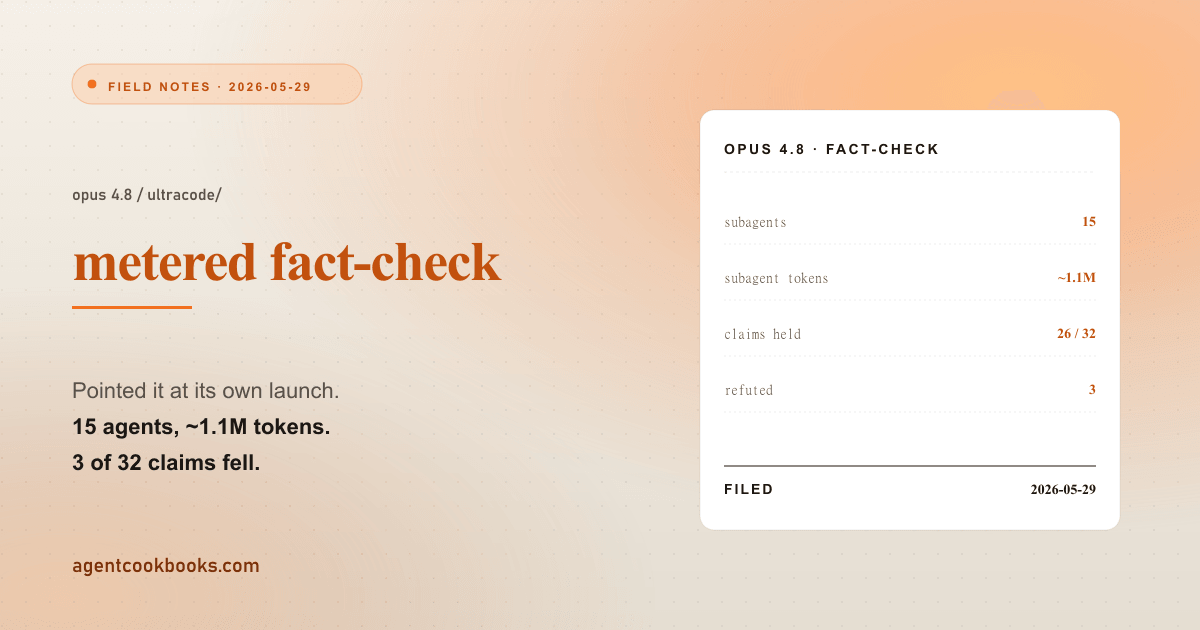
This site runs on Opus 4.8. The model picker is on Default, which resolves to claude-opus-4-8 with a 1M-token context, and the Effort control is pegged at its top notch — labeled Ultracode, which pairs xhigh reasoning effort with Dynamic Workflows, the multi-agent orchestration the launch writeup is built around. So instead of paraphrasing that writeup — which would violate the one rule this site has — I pointed the feature at it. A Dynamic Workflow fanned 15 subagents across 7 claim clusters to check 32 specific claims about the model against primary sources, with an adversarial second pass told to default to disbelief. It cost about 1.1M subagent tokens (~108K of them output), 161 tool calls, and ~11 minutes of wall-clock. Twenty-six of the 32 claims held. Three were single-sourced. Three were wrong as written — including a fast-mode price that doesn’t exist anywhere in Anthropic’s docs. The non-obvious part is in the last section: the launch post credits the model with catching its own mistakes, but the mistakes here were caught by skepticism I scripted into the harness, and from the operator’s seat you can’t cleanly tell the two apart.
The settings we’re actually running
The screenshot that kicked this off shows the exact config every word below was produced under:
Model: Default → claude-opus-4-8 (1M context)
Effort: Ultracode (= xhigh effort + Dynamic Workflows)
Thinking: onFour things the workflow confirmed about that control, all against Anthropic primary sources:
- High is the default effort, on every surface including Claude Code and the Messages API. We’re not on the default; we’re a notch past it.
- xhigh is what
claude.aicalls “Extra.” Same level, different label depending on where you’re sitting. The Effort slider’s “Ultracode” entry is not a higher effort level than xhigh — it’s xhigh effort plus the multi-agent (Dynamic Workflows) permission bundled together. - The effort levels were recalibrated from 4.7 to 4.8. Anthropic’s migration guide is blunt about it: medium now allocates somewhat more thinking, high somewhat less, and xhigh substantially more. If you tuned a cost or latency budget against an effort level on 4.7, re-baseline before you trust it. Our xhigh is doing more per turn than the same word did three weeks ago.
- The launch writeup’s effort list is incomplete. It presents High / xhigh / Max as the set. The API actually accepts five — low, medium, high, xhigh, max — and the docs call that “the complete set the API accepts.” That’s the first of three claims that didn’t survive.
What I pointed it at
I didn’t let the model auto-plan this; I scripted the workflow so the structure was deterministic and the cost was bounded. Seven claim clusters — release/pricing, benchmarks, the self-review claim, effort controls, Dynamic Workflows itself, the API/integration claims, and the Bun migration demo. Each cluster ran two agents in a pipeline: a research agent that searched the open web for an Anthropic primary source (the announcement, platform.claude.com, the model card) or two independent outlets, then a verify agent that took the first agent’s findings and tried to knock them down — explicitly told to mark a claim single-source-only rather than holds whenever the only support was one blog. A final synthesizer merged seven cluster verdicts into one table. The pipeline shape means verification on the early clusters started while the later clusters were still searching; no barrier in the middle.
That is, at hobby scale, the same move Anthropic demoed at production scale: the launch’s headline case study is a Zig-to-Rust port of Bun — ~750,000 lines of Rust, 99.8% of the existing test suite passing, eleven days, hundreds of agents in parallel with two reviewers per file. Every one of those figures held against the Anthropic write-up of the Bun port. Mine reviewed a blog post instead of a compiler, and used 15 agents instead of hundreds, but it’s the same primitive.
What it cost
The receipt, straight from the run’s usage meter:
- 15 subagents spawned (7 research + 7 verify + 1 synthesizer).
- ~1.1M subagent tokens total — but only ~108K of those were output. The other ~90% is input: the workflow pulled a lot of web-page content into context to read it. Verification fan-outs are input-dominated, which is the opposite of what “1.1 million tokens” makes you picture.
- 161 tool calls across the 15 agents.
- ~11 minutes wall-clock (641 seconds).
This is the concrete version of the launch post’s “Dynamic Workflows consume meaningfully more tokens than a normal session” — a claim that holds, on secondary sourcing. A single bounded fact-check of one blog post moved more than a million tokens. My run never came close to the ceiling, though: the harness caps concurrent subagents at min(16, cores − 2) and the lifetime total at 1,000 per run — the exact caps the secondary coverage reports — and I used 15. The ceiling is built for the 750k-line migration. Most tasks want a dozen agents and a spending limit, not the ceiling.
What didn’t survive
Twenty-six of 32 held — better than most launch-day coverage, and the writeup deserves credit for being un-hyped to begin with. The value was in the six that didn’t, and especially the three that were wrong as written:
| Claim as written | Verdict | What’s actually true |
|---|---|---|
| Fast Mode is $1.25 / $6.25 per M tokens | refuted | Opus 4.8 Fast Mode is $10 / $50 per M (Anthropic docs). $1.25 is Haiku 4.5’s cache-write rate on the same page — likely where it was mis-sourced. The 3× cheaper than prior Opus fast mode line holds ($30/$150 → $10/$50); Fast Mode is still a 2× premium over the standard $5/$25. |
| Effort levels are High / xhigh / Max | refuted | The API accepts five — low, medium, high, xhigh, max. “Ultracode” is not a sixth level. |
| The “2026 control syntax” dropped temperature/top_p/top_k → 400 error | refuted | The 400 error is real but unchanged — it shipped with 4.7, the docs literally label it “(unchanged).” And “2026 control syntax” appears in zero Anthropic sources; it’s an invented label around real 4.7-era behavior. |
| OSWorld-Verified 83.4% vs 82.8% (4.7) | single-source | The 4.8 = 83.4 holds; the 82.8 baseline is disputed — Anthropic’s own footnote says 82.3, other outlets say 78.0 pre-fix. Three different baselines float around. |
| Code-summary honesty: fails to flag events 3.7% of the time | single-source → since verified | The card was too big for WebFetch (>10MB), so the workflow couldn’t open it. Converted later with MarkItDown: confirmed from the primary — “…only 3.7% of the time, down 5-fold from Mythos Preview, which misleads the user 27.6%…” — which also pins the denominator. |
| Dynamic Workflows is default-on for Max/Team | single-source | Anthropic confirms plan availability but is silent on default-on. The “default-on” detail is secondary-only. |
Update (2026-06-01): one of the three single-source claims above — the 3.7% honesty figure — has since been verified from the primary system card; see the follow-up. The tally above reflects what the workflow could corroborate at the time of the run.
For balance, the load-bearing claims held hard. SWE-Bench Pro 69.2% (up from 64.3%), the unchanged $5/$25 standard pricing, the GitHub Copilot 15× premium multiplier until usage-based billing lands, the existence of a more capable gated “Claude Mythos” model this one bridges toward — all corroborated on a primary source plus independent outlets. So did the headline. Anthropic’s announcement, verbatim: “Opus 4.8 is around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.”
Where it drifted — model honesty vs. harness skepticism
That “four times” line is a claim about the model: left to its own judgment, 4.8 flags its own bad code more often than 4.7 did. It held against the primary source, and it’s the most interesting thing in the launch.
But notice what actually caught the three refuted claims in my run. Not the model noticing, mid-thought, that a number smelled wrong. A web search hit platform.claude.com and returned $10/$50; a verify agent I had explicitly instructed to distrust single sources refused to upgrade “default-on” past single-source-only. That’s harness scaffolding and tool use doing the work — prompted adversarial review, not unprompted self-verification.
Every one of those subagents is Opus 4.8, so the model’s judgment is threaded through all of it. But I engineered the skepticism. The “four times” claim is about unprompted self-review; my setup is the prompted, adversarial kind. They are different mechanisms that happen to point the same direction, and when you run with Ultracode you get both at once.
The practical consequence: you can’t use your own Ultracode session to confirm the model’s self-verification claim. The eval behind “four times” is Anthropic’s measurement — treat it as theirs. What a fact-check workflow proves is narrower and still worth the tokens: pointing a skeptical fan-out at a confident text reliably surfaces the handful of numbers that were invented or single-sourced. On this writeup that was three of thirty-two. Paraphrasing it instead — the thing this site exists not to do — would have shipped all three.
Takeaways
- Treat launch-post numbers as claims, not facts. A genuinely good, un-hyped writeup still carried three wrong specifics. The fix isn’t distrust, it’s a cheap verification pass before you repeat anything.
- Dynamic Workflows is verification-shaped. Fan-out research plus an adversarial check is exactly what the primitive is good at, and you script the skepticism in — don’t assume the model supplies it.
- Meter it, and cap it. One blog-post fact-check was ~1.1M tokens. The 1,000-agent ceiling is for migrations; everything else wants a dozen agents and a budget.
- If you tuned effort on 4.7, re-baseline. xhigh allocates substantially more thinking on 4.8 than the same setting did on 4.7. Your old cost and latency assumptions are stale.